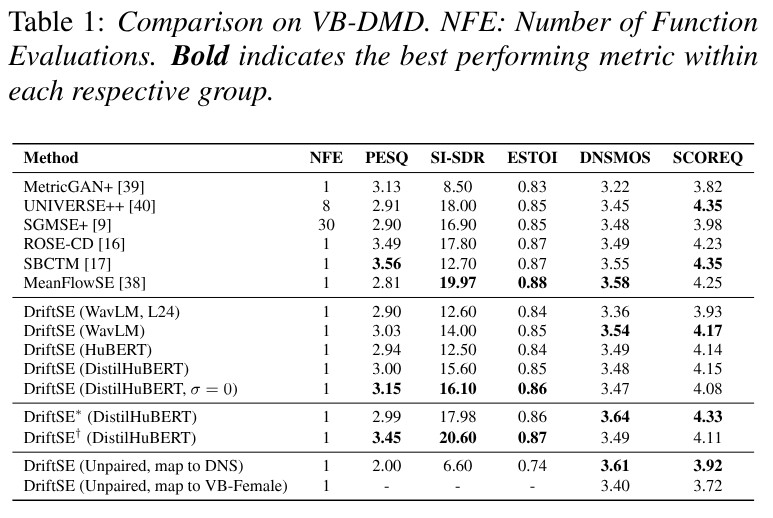
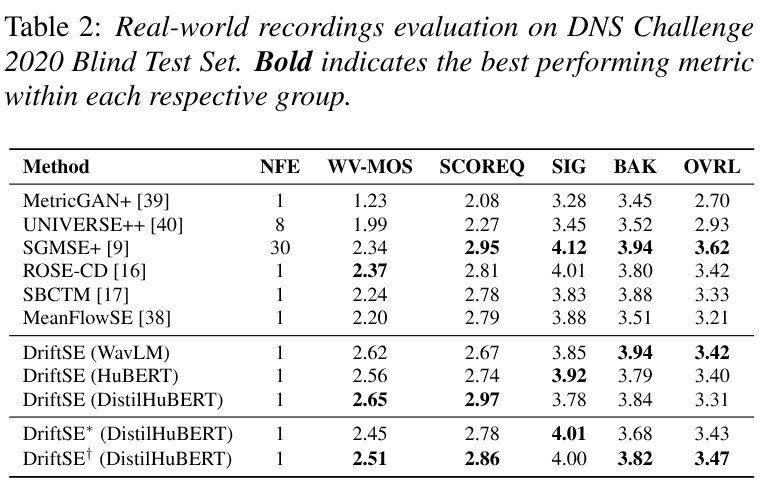
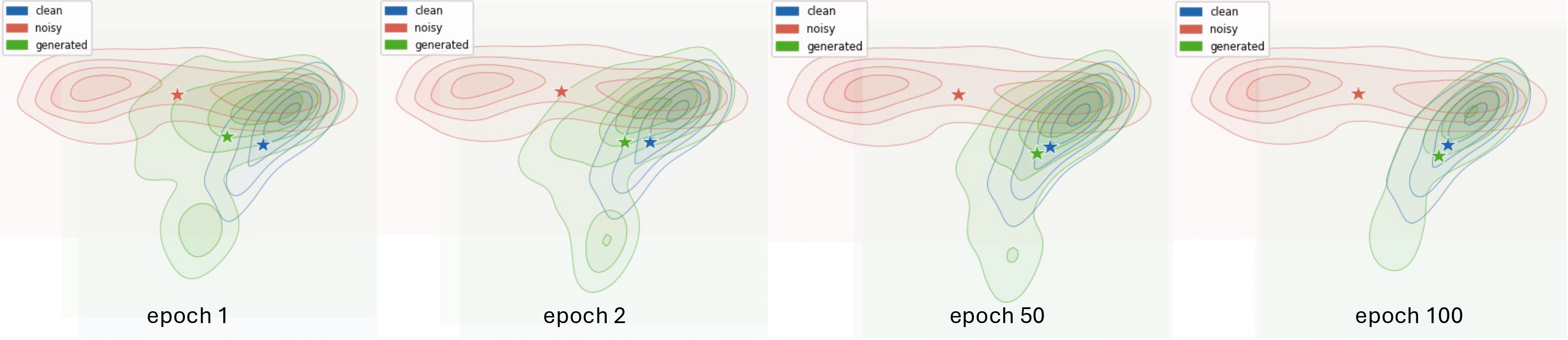
Overview of the proposed DriftSE

We present DriftSE : Speech Enhancement based on Drifting Models (DriftSE), a novel generative framework that formulates denoising as an equilibrium problem. Rather than relying on iterative sampling, DriftSE natively achieves one-step inference by evolving the pushforward distribution of a mapping function to directly match the clean speech distribution. This evolution is driven by a Drifting Field, a learned correction vector that guides samples toward the high-density regions of the clean distribution, which naturally facilitates training on unpaired data by matching distributions rather than paired samples. We investigate the framework under two formulations: a direct mapping from the noisy observation, and a stochastic conditional generative model from a Gaussian prior. Experiments on the VoiceBank-DEMAND benchmark demonstrate that DriftSE achieves high-fidelity enhancement in a single step, outperforming multi-step diffusion baselines and establishing a new paradigm for speech enhancement.
Noisy Input
Clean Reference
SGMSE+(30 steps)
ROSE-CD
DriftSE
Noisy Input
Clean Reference
SGMSE+(30 steps)
ROSE-CD
DriftSE
Noisy Input
Clean Reference
SGMSE+(30 steps)
ROSE-CD
DriftSE
Noisy Input
DriftSE (paired)
DriftSE (unpaired, map to VB-Female)
Noisy Input
DriftSE (paired)
DriftSE (unpaired, map to VB-Female)
Noisy Input
DriftSE (paired)
DriftSE (unpaired, map to VB-Female)
@inproceedings{xu2026driftse,
author = {Liang Xu and Diego Caviedes-Nozal and W. Bastiaan Kleijn and Longfei Felix Yan and Rasmus Kongsgaard Olsson},
title = {Speech Enhancement Based on Drifting Models},
booktitle = {Proc. Interspeech 2026},
year = {2026}
}